This page documents a previous project that was done in the early years of my schooling. The reason for posting this on the blog is due to an ongoing effort to modernize the site.
What did this do?
This was an attempt to organically drive views to other project pages via previous user behavior. This was a very simplified attempt at doing a localized PageRank suggestion system.
In more detail please..
This software takes all the user activity data, fitting a URL pattern from the logs, converts them into time based sessions, and converts the sessions into Page bigrams. The end result is a parent page, neighboring pages [children], and their probability. From there the data is represented as an XML document, which can easily be updated and referenced within the website by using XPath, and XSLT.
Fast Breakdown
- Language(s): Java
- Creation Date: ~2011ish
- Audience: Website visitors
- Methodologies/Technologies: Java, XML, XStream, JUnit, Git, Apache HTTP Log files, Bash, Cron, Offline processing, and XSLT
- Purpose: Personal Project, released as open source software
- Github Link: GH: monksy/PageRecommender
- How was this executed? Cron job as a standalone executable
- Current Status Depricated and the old site is no longer.
Screenshots
On the old site, this is the finalized result that it produced:
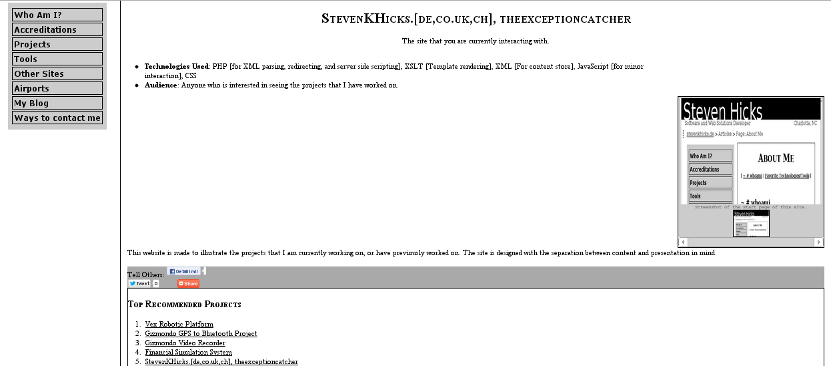
Problem and Constraints
With the older site (as can be seen in the screenshot), there was an issue with user retention and exploration. I wanted to replicate the behavior of sites like Amazon that could make recommendations for the user to view other projects.
The scale of the problem didn’t warrant a large server, additionally the data I had available to me was the Apache Log files.
How did I solve the problem?
- I gathered the data that I had
- I identified the context of the situation (I’m using Apache, a self hosted server, a linux environment, etc)
- I created an application that would reduce down the log files into frequency based collections and outputted them to an XML document.
- Added in the XML document into the page.
- Test and release
Other thoughts
The solution was to create a bigram model of all the project pages and their next visited page [neighboring page]. A bigram model gives the probability of going from one page to another. Additionally, to fight a concern about multiple sessions, with the same user, there is an attempt to split out those sessions by time. Individual sessions give a more representational view of what is determined as a cluster. If a user is to view the page on my website and my web browser and then come back an hour later and view pages about the Financial Analysis project and the eBook collection system, it is assumed that these are two different/unrelated clusters. After splitting out the sessions, the bigram output gives an overall view of what the user is more likely to view next.
Other approaches that could have been used are Bayesian statistics, neural networks, document analysis, or even Google’s PageRank algorithm. I chose to go with a basic bigram approach for a few reasons. First, the solution, bigram based, is easy to implement and test. Secondly, the document space is rather small. If I threw a heavy weight clustering or document analysis approach at this problem, the results would not be very useful, there would be a heavy emphasis on how similar the pages are. Humans make connections based on what they want to see. The computer only has the ability to make a guess at what that may be. I’m more interested in the user’s behavior than the computer’s prediction of what may be motivating the user. Thirdly, Bayesian networks/statistics would be overkill for this problem. Clusters are implied however, I am not interested in making a classification; I’m interested in establishing a strength-based relationship between two documents. Google PageRank would be overkill for creating recommendations as that I’m not concerned about the level of trust between the pages as they are coming from the same level of credibility [my site] and if a user is to leave the site then a recommendation is not useful.
Success
After implementing this, I saw an increase of pages that users navigated to from a project page. Since project pages have a higher SEO value, this lead to increase usage in the site. Since the site isn’t monetized, it didn’t result in any additional revenue.
User impact
The user impact had one small additional static request on page load. But other than that, there was no impact to the system, the functionality was quick and readily available. Additionally, since the static content didn’t change from page to page: The browser cache sped up the page loading process.
Performance and Automation
This project runs independently of the website’s operations. There is little need to run the project online with each request for a page. This also means that if the data is moved to another server, the task could be handled outside the web server. The relationships tend to converge over time, and change very rarely. This project is run as a daily job, and if the task fails, then no data is overwritten. The website is unaffected by a failure of the component. The user may not receive the results of the recommendation service, or the results may be considered to be “stale.” Displaying stale information is better than a website failure due to the component. Since this is a non-blocking process, as a result no users will experience downtime, nor will the server’s ability to serve up content be affected. The project can be easily adapted to become an online system as that the data structures are designed to be immutable and be inflexible to change. However, the main logic flows will have to be adapted into more of a Map/Reduce like design.